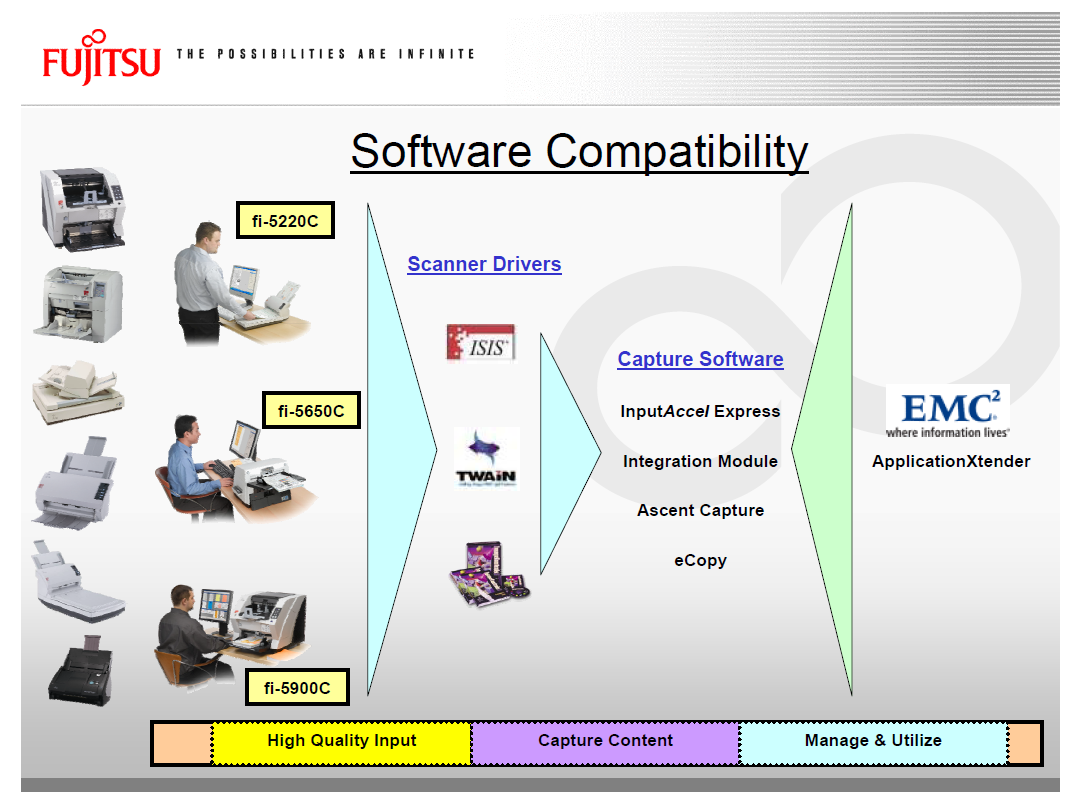
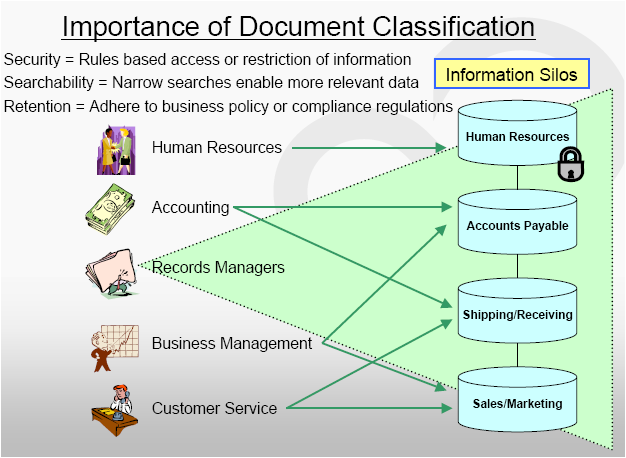
Network Scanner extravaganza! AIIM 2009

As product manager for the Fujitsu fi-6010N network document scanner I was extremely passionate about my product and never was this more apparent than at our industries largest trade show expedition every year, AIIM. About AIIM AIIM (Association for Information and Image Management) is the global community of information professionals. We provide the education, research and certification that information professionals need to manage and share information assets in an era…