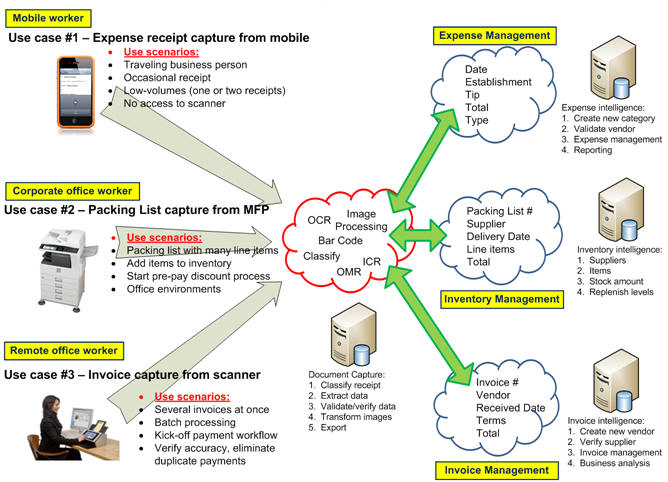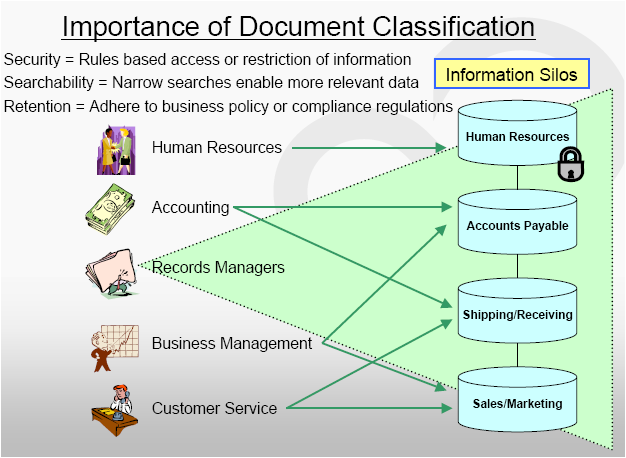
The logic of document capture
Indexing, Metadata, Keyword, SharePoint, Capture, Scanner, Documents, ECM, Content Management What is wrong with the collection of words above? Well, it’s a collection of terms that are closely related but have no logical structure in order to be of value to anyone reading them. In order for these words to be valuable in terms of […]
The logic of document capture Read More »