
Electronic Medical Records increase wait time. Really?
Electronic Medical Records increase wait time. Really? Read More »
Technology related items.

Leveraging an investment in scanning hardware and software should always be a priority. After all these are typically not cheap investments although the ROI can be outstanding if implemented properly. In this blog I would like to share some little known, yet extremely useful, features that can dramatically improve forms processing automation and accuracy. I
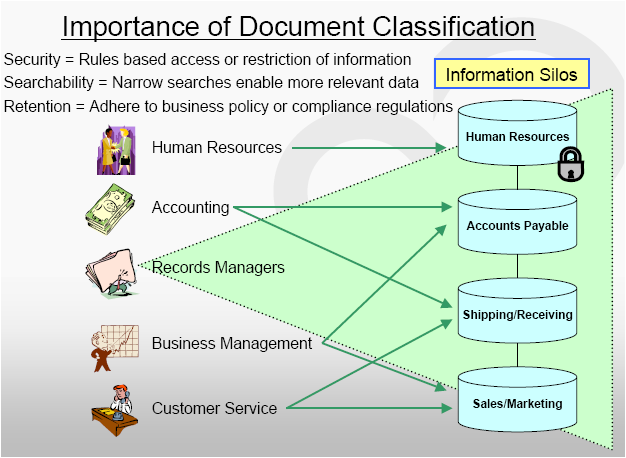
Indexing, Metadata, Keyword, SharePoint, Capture, Scanner, Documents, ECM, Content Management What is wrong with the collection of words above? Well, it’s a collection of terms that are closely related but have no logical structure in order to be of value to anyone reading them. In order for these words to be valuable in terms of
The logic of document capture Read More »
Capture begins with process As a prelude to an upcoming series of blog posts I will be posting on the topic of “Building an effective capture solution” I wanted to preface these posts and focus on the question of ‘where do I start if I want to build an effective capture solution?’. More education, less
Capture begins with process Read More »

Is your SaaS value proposition convincing enough without automatic data entry? Imagine you’ve just created the next ‘killer’ Software as a Service (SaaS) app and you are absolutely convinced your new software service is going to revolutionize a particular industry or solve a significant pain point for organizations all over the world. You create some
Your killer SaaS app Read More »