Indexing, Metadata, Keyword, SharePoint, Capture, Scanner, Documents, ECM, Content Management
What is wrong with the collection of words above? Well, it’s a collection of terms that are closely related but have no logical structure in order to be of value to anyone reading them. In order for these words to be valuable in terms of readability for context they need to be logically organized into a sentence. The logic of document capture and Enterprise Content Management is much the same. In this blog post, instead of going into the nuts and bolts of document capture I thought it is more important to discuss two critical components to your overall success, or failure, of your content management strategy. These two critical components are taxonomy and metadata. This is philosophy and not technology.
To break down document capture in its simplest form, just think of this as the process of extracting information from a document and making that information available in the future. The future could be immediate where a scanned invoice, for example, immediately kicks-off a payment process. Or it could be two weeks from now where a customer service agent needs to retrieve a signed airbill for a proof of delivery. The point is that document retrieval is based on some unique keyword or a set of keywords related to a particular document. In the case of the invoice it could have been the invoice number and in the case of the airbill it could have been the shipping tracking number.
If you do not consider a well thought-out strategy then your organization could have accomplished the task of taking an organized paper mess and simply converted it to an electronic mess.
Establish a well thought-out taxonomy
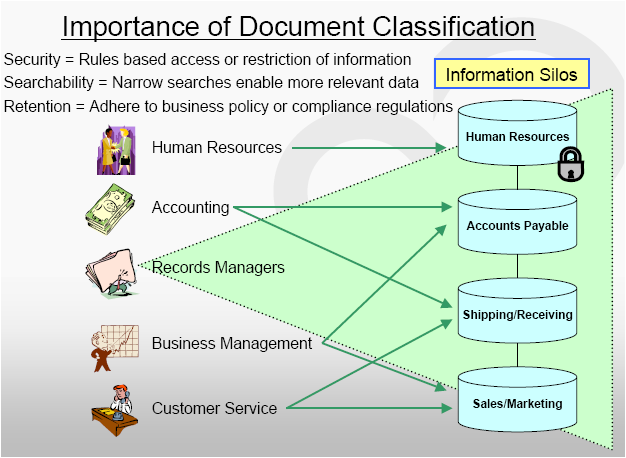
Taxonomy is defined as classifying organisms into groups based on similarities. Why is taxonomy relevant for document capture? For several reasons, including security, quicker access to information and retention policies. So, if you work backwards in the methodology of how and what, technology to implement for your document capture solution a solid consensus of the end result is of paramount importance. The end result is typically a high-quality scanned image conducive for data capture (OCR, ICR, OMR, bar code, etc.) and the metadata itself. So if your taxonomy has organized methodology then it should assist in making your document capture strategy fairly obviously. Let’s take security as a benefit for a well thought-out taxonomy strategy. By segregated documents based on a logical taxonomy, organizations are afforded an addition level of comfort knowing that a set of security policies can be applied to, for example, Human Resource, documents allowing access to everyone for a general set of available scanned documents such as the café menu which is clearly not a information sensitive document. Additionally, another benefit of a well thought-out taxonomy is quicker access to information for users. Many content management software applications and search engines use a ‘crawl’ method to check newly added content and add them to an index (database) which is then searchable. As you can imagine, common sense and logic dictates that ‘crawling’ a more narrow scope is much quicker to keep the database up-to-date, but also access times could be considerably less by not having to search the entire database and only the relevant data indexed. This makes access to data quicker. Lastly, in regards to retention policies, having your data well organized is a major benefit for this area. Imagine that an organization has all of their tax documents properly electronic stored via a well thought-out taxonomy in their content management system. If they did then easily, and within corporate governance standards and policies the organization can removed these images from their repository based on a retention schedule. So, as illustrated, investing the time to develop a strong taxonomy is important for many reasons including security, searchability and retention.
It is extremely important to not over look this important concept when planning out a document capture strategy. A simple taxonomy might be organized like below:
- Accounting
- Accounts Receivable
- Check
- Statement
- Accounts Payable
- Invoice
- Receipt
- Accounts Receivable
- Human Resources
- Applications
- Resumes
- W2 Forms
Considering a well thought-out strategy might seem cumbersome in the initial stages of establishing your document capture strategy, but it can save organizations significant time, money and aggravation in the long-run. As a best document capture practice it is important to establish a solid taxonomy for scanned documents and also re-evaluate the strategy as it relates to taxonomy as any new documents are introduced within your organization.
Consider what information is important, and what is not
Creating Searchable PDF’s is one form on document capture; however, it is not always an ideal document capture strategy. While sometimes, in certain situations, creating Searchable PDF images of your scanned documents is the right approach for an organization sometimes this technique of document capture often creates inefficiencies. You might be thinking to yourself how could creating a fully Searchable PDF with all the words of the document indexed be construed as being inefficient? Let me elaborate. When creating a Searchable PDF the scanning software does its best job possible to recognize every single character and every single word on a page. This might sound appealing but let’s consider the possible results in real-world applications. Imagine that an organization in the insurance business scans as little as 100 single-page documents and creates Searchable PDF documents. Then they want to retrieve a document based on a keyword so they use the word “claim” in their search criteria to find a document a user is searching for. As you can imagine the user would most likely be presented with a long set of links to possible documents but only one is the important document they are looking for and the rest is “irrelevant search”. This is because the entire page was indexed via the Searchable PDF method. Alternatively, if your data capture strategy had included only extracting “relevant search” terms that apply to a particular document then you make the organization much more efficient by being able to find the data you have requested much quicker with the first search.
One of the other significant benefits with an integrated document capture/content management strategy is that often times any sort of metadata fields created, and rules applied, in the content management system can be brought forward and applied into the document capture system itself. For example, if an organizations’ policy dictates that on a healthcare insurance form that for a metadata field the social security number is required and can only be nine characters long of numeric characters, then directly in the document capture system these rules can be enforced. This allows for great business continuity and consistency in your data capture process.
An analogy I like to use is go to your favorite internet search engine and enter in a vague term such as “taxonomy for document capture” then you will get a long list of ‘hits’ that probably are not of interest because you might be looking for a specific piece of information, or a scanned image. In the contrary, if the user enters-in a more specific term such as “aim document taxonomy” then the focus of the search is narrowed down to a more relevant list of potential information the user is searching for. This is an example of relevant search versus irrelevant search and it’s all related to applying metadata to web pages, electronic documents and, yes, especially scanned images.
Summary: Organized taxonomy + relevant metadata = Efficient process
In summary, my point is to carefully plan out your document capture process. Pay close attention to developing an effective taxonomy for your documents. Determine what information is important on a particular document and what is not. Document capture technology has evolved to nearly magically proportions but, the truth is that organizations can still greatly help their efficiency and content management effectiveness through careful planning; after all there still is logic to document capture.
Do you have thoughts of the topic of document capture, taxonomy or classification? Please share your comments.